Planteamiento instrumental del inventario: pruebas realizadas y resultados obtenidos
19
B
ases
para
la
realización
del
S
istema
C
ompartido
de
I
nfomación
sobre
los
P
aisajes
de
A
ndalucía
: A
plicación
a
S
ierra
M
orena
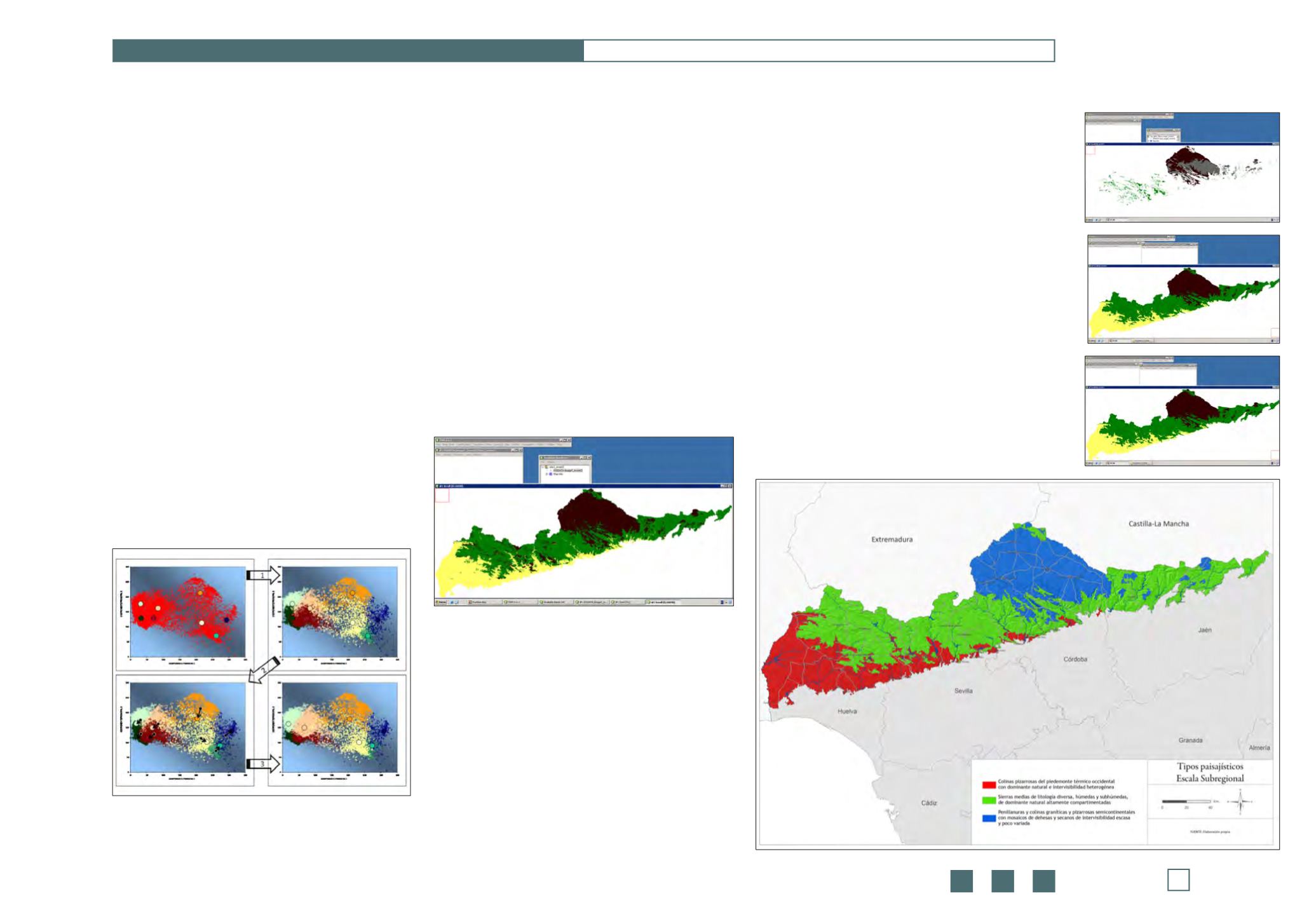
Fase4. Análisis deClasificaciónNo Supervisada
El análisis de clasificaciónno supervisada es un análisis ex-
ploratoriode losdatosque consisteen clasificar unamues-
tra sinpatronespredefinidos. En lenguaje coloquial, podría
definirse como realizar una clasificacióna ciegas.
Se ha considerado a la clasificación no supervisada como
especialmenteadecuadapara la identificacióndetipospai-
sajísticos, yaque sonentidades denaturalezaabstracta, de
difícil concreción para lamente humana bajo patrones re-
producibles espacial y temporalmente.
El programa estadístico de clasificación de imágenes
ENVI
pone a disposición del usuario dos algoritmos para la rea-
lización de clasificaciones supervisadas:
K-Means
e
ISO-
DATA
. Ambos son análisis de clasificación no supervisada
restringidos (el númerode clases en laque seestructura la
muestra es definido previamente por el usuario) y de rea-
grupamiento, ya que realizan un primer reagrupamiento
que se va refinando iterativamente. Dehecho, el algoritmo
ISODATA
es frutodeun intentodemejora realizadosobreel
algoritmo
K-Means
. En la práctica, dependiendo de lama-
triz de datos con la que se esté trabajando, se obtendrán
mejores resultados con uno u otro algoritmo. Así, se han
realizado pruebas con ambos y el quemejores resultados
ha reflejado en este caso, tras la revisiónde la distribución
espacial de los grupos por el equipo de investigación del
inventario, ha sido
ISODATA
(
Iterative Self-OrganisingData
Analysis Technique
) (TouyGonzález, 1974).
El algoritmo separa todos los píxeles enel rangode grupos
distintos especificados por el usuario en el espaciomulti-
dimensional. Dicho algoritmo es unproceso repetitivoque
calcula ladistancia Euclídeamínima cuando se asigna cada
píxel aunclúster. El procesocomienzacon laasignaciónpor
parte del software demedias arbitrarias para cada clúster.
Cada píxel es entonces asignado a la más cercana de las
medias. Se recalculannuevasmedias para cada clúster ba-
sándoseen lasdistanciasde losatributosde lospíxelesque
pertenecen al cluster después de la primera repetición. Se
repite el proceso: cada píxel es asignado a la media más
cercana en el espacio multidimensional de atributos (va-
riables) y se calculan nuevas medias para cada cluster ba-
sándose en los píxeles miembros de cada cluster desde la
repetición. El número de repeticiones del proceso puede
serespecificadoporel usuario; enel presenteestudio: 100.
Este valor debe ser lo suficientemente grande para asegu-
rar que tras el número de repeticiones especificado, lami-
graciónde lospíxelesdesdeunclusteraotroseamínima, lo
queevidenciaque los cluster sehan vueltoestables.
Fase 5. Depuración
Para el depuradode la clasificación, se ha realizado la sub-
división de cada uno de los 3 tipos paisajísticos previos
(mostrados en la imagen anterior). La subdivisión del tipo
paisajístico previo (“pedrochense”), ha sido la única cuyos
resultados han servidoparael depuradode la clasificación.
Uno de los subtipos tiene una distribución territorial muy
semejante a la de uno de los tipos previos. Tras analizar la
importancia relativade lasvariablesparael subtipoyeltipo
indicado, se comprobó que tenían un elevado grado de si-
militud.Tantoesasíqueseoptóporsu fusión, consiguiendo
un primer depurado de la clasificación siguiendo criterios
reproducibles.
Tras la inclusión del subtipo y el tipomencionados, se ha
sometido la clasificaciónaunfiltrado.
Por último, se han eliminado todas aquellas islas con un
tamaño inferior a1ha. A continuación semuestrael resul-
tadofinal de la identificacióndetipos paisajísticos a escala
subregional (T2).


